Эта заметка — про то, как я писал программу, которая:
Практической пользы в этом не очень много, так как в современных реалиях очередная рисовалка карт, да ещё и работающая только для одного города, нужна примерно никому (особенно в эпоху повсеместного распространения векторных плиток). Тем не менее, это был интересный челлендж и отличный образовательный хобби-проект — пока я над ним работал, я узнал (иногда по своей воле, иногда не очень) десятки любопытных новых вещей про 2D-графику, картографические проекции, арифметику с плавающей точкой, алгоритмы парсинга, экосистему языка Rust и другие смежные области.
Вот так выглядел куцый прототип в 2017 году, когда я ещё не собирался закапываться сильно глубоко, а просто хотел максимально быстро и просто нарисовать карту-подложку для маршрутизатора:
А вот как выглядит сейчас — в состоянии, которое я бы назвал “feature complete”:
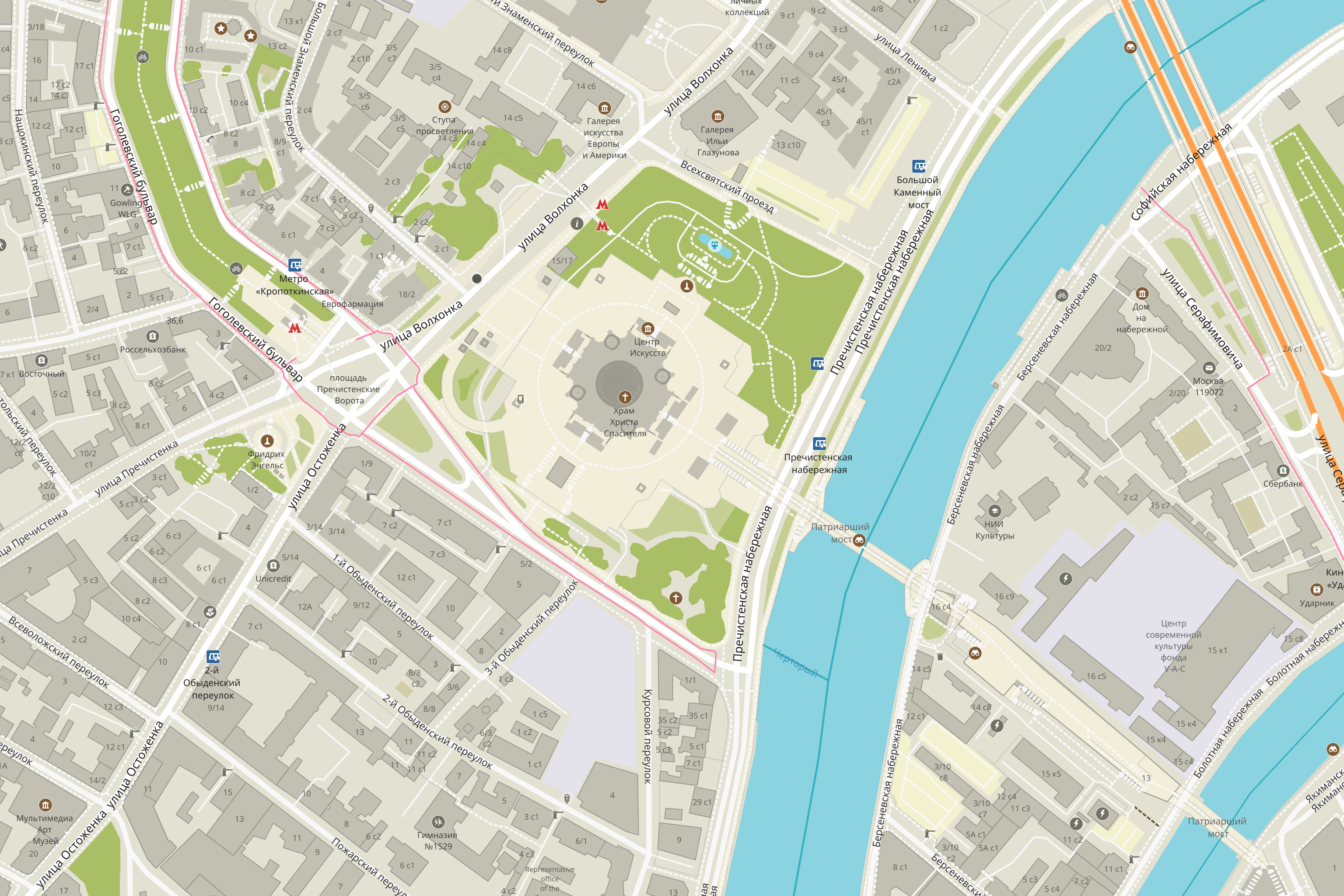
(для тех, кому одной картинки мало, есть ещё демка с нарисованной Москвой)
Дальше заметка устроена так: я постарался вспомнить интересные относительно крупные подзадачи, которые возникали по ходу хобби-проекта, и написал по параграфу на каждую. Между собой эти подзадачи связаны не сильно, поэтому параграфы можно читать более-менее независимо друг от друга.
В протоколе Slippy Tiles, который реализует любой уважающий себя рендерер, есть 19 уровней масштаба (от 0 до 18). На нулевом уровне весь мир накрывается одной плиткой, на первом уровне — четырьмя (плитка нулевого уровня разбивается на четыре подплитки), на втором — шестнадцатью, и так далее.
Для одного города что-то осмысленное в конкретной плитке можно увидеть начиная примерно с 11-го уровня:
Эта плитка состоит из 16384 подплиток самого крупного (18-го) уровня, вот таких:
Соответственно, перед тем, как что-то вообще рисовать, нужно узнать, какие географические объекты (дома, улицы, скверы, озёра, кладбища) попадают в запрашиваемую плитку. Понятно было, что если хочется делать это быстро, то надо заранее построить подходящий для этой цели индекс, причём желательно такой, чтобы его было максимально просто mmap’ить.
Судя по интернетам, лучше всего для индекса по геоданным подходит классическое R-дерево, а для статических геоданных — алгоритм его построения под названием Sort-Tile-Recursive. Но чтобы побыстрее получить первые результаты, я сначала на коленке соорудил быстрый хак:
(x, y)-координатам плитки и сохраним на диск;Неожиданно для меня этот хак заработал быстро (так ни разу и не увидел его в профайлере) и практически с первого раза, так что R-деревья так и не пригодились, а пресловутый бинарный поиск, кажется, оказался единственным нетривиальным участком кода, который остался нетронутым с начала проекта.
(в скобках отмечу неприятный сюрприз, когда для Екатеринбурга построенный индекс оказался в несколько раз больше исходного файла с геоданными. К счастью, удалось быстро найти виновника — я вырезал Екатеринбург из Свердловской области утилитой osmconvert с ключом --complete-ways, и она решила притащить мне в подарок трассу «Екатеринбург — Челябинск», по понятным причинам непомерно раздувшую конечный результат)
Хотя алгоритм поиска получился простым, как 3 рубля, сам код, обрабатывающий индекс по геоданным, не так прост — на него приходится 13% строчек кода рендерера и 100% использований ключевого слова unsafe (которого программисты на Rust избегают как огня). Однако по сравнению с C++ отображать байты в память и жонглировать ими намного приятнее:
memmap-rs с единым интерфейсом поверх mmap() (на POSIX-системах) и CreateFileMappingW/MapViewOfFile (на Windows). Поэтому из коробки всё работает на Windows, Linux и macOS (и наверняка ещё много где, но я тестировал только эту святую троицу);read_u32/read_f32/…) вместо обычных C++-заклинаний с memcpy() и вычислением того, сколько байт нужно скопировать;Одна раздражающая неэргономичность, впрочем, — полиция borrow checking запрещает сохранять рядом структуру, владеющую mmap-указателем, и структуру, содержащую этот же указатель без владения им. Приходится легализовывать такой паттерн сомнительными способами и городить лишний unsafe на ровном месте.
Когда известно, какие объекты входят в плитку, надо определиться, как их рисовать — что уместно показывать на текущем масштабе, какие цвета и шрифты использовать, насколько толстые должны быть линии. Всё это вместе традиционно называется картостилем. Моё чувство прекрасного сразу подсказало мне, что с моим чувством прекрасного картостиль лучше не пытаться изобретать самостоятельно, а вместо этого научить рендерер использовать уже что-то готовое.
Оказалось, что единого стандарта на описание OSM-картостилей нет; есть несколько разных форматов (MapCSS, CartoCSS, Mapbox GL), со своими преимуществами и недостатками. Мне в итоге подошёл только MapCSS — он единственный позволяет стилизовать сырые OSM-данные, все остальные требуют сначала импортировать их в PostgreSQL или ещё куда-то.
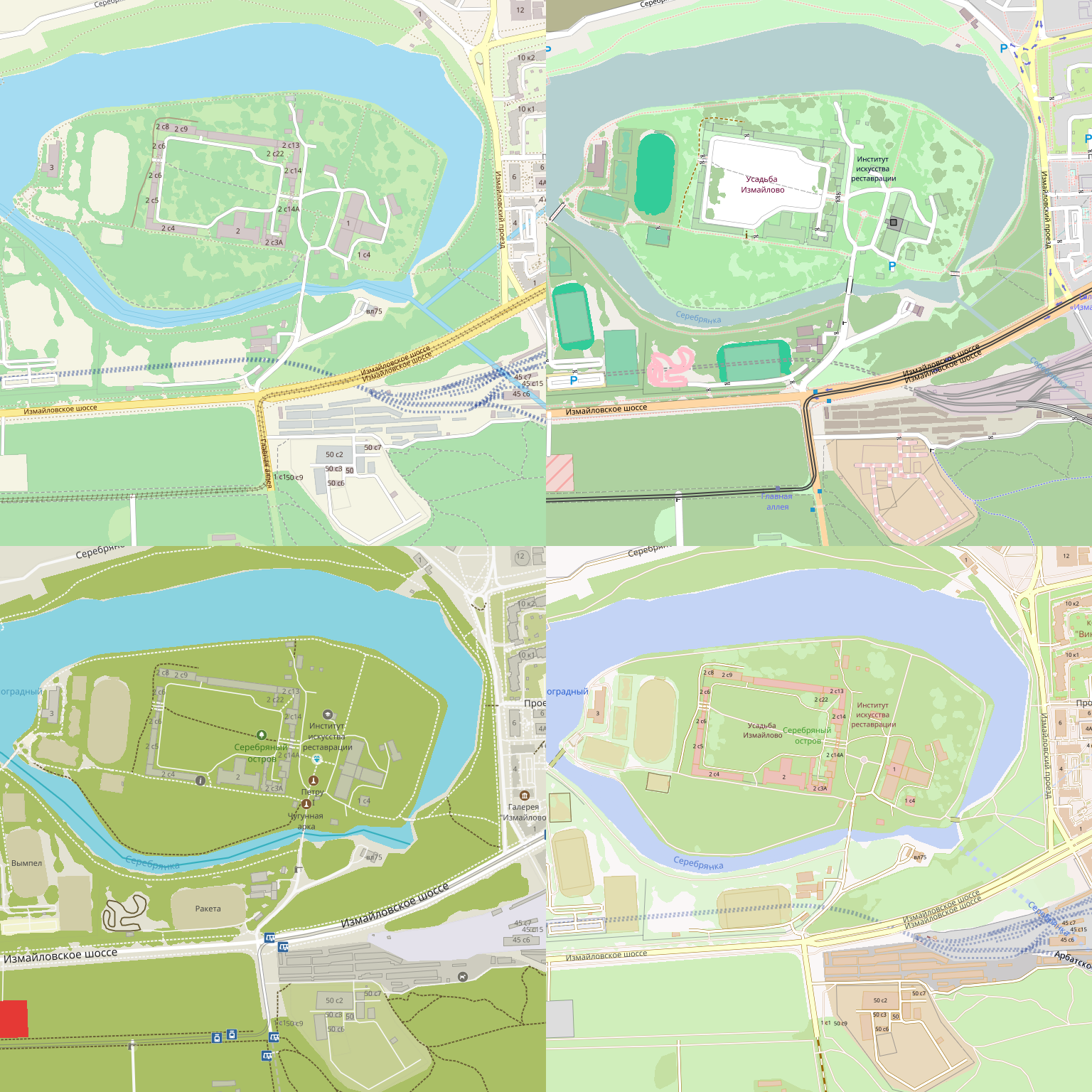
Сейчас MapCSS почти что мёртв — из известных проектов его используют только Maps.ME и GuruMaps, поэтому новых стилей в нём не появляется. Но это не беда: уже написанных стилей достаточно, чтобы было из чего выбирать. Вот так по-разному может выглядеть одна и та же местность:
Довольно логично, что по внешнему виду MapCSS очень напоминает обычный CSS — те же самые каскады правил, только селекторы выглядят по-другому:
// Применяем свойства к паркам, начиная с 11-го уровня масштаба
area|z11[leisure=park] {
// В центре парка пишем его свойство "name" шрифтом высотой 10
text: name;
font-size: 10;
text-position: center;
// Заливаем парк цветом зелёного чая
fill-color: #DCF2CB;
// Задаём вертикальную позицию парков относительно остальных объектов
z-index: 12;
}Как и в случае большого CSS, несмотря на обманчивую простоту правил и на наличие (неформальной) спецификации, найти две полностью соместимые между собой реализации MapCSS невозможно. Поддержка всех разнородных диалектов и конструкций обходится не бесплатно — 30% кода рендерера (без учёта тестов) приходится на каталог mapcss/, в котором находятся токенизатор, парсер и сама применялка распаршенных стилей — и хорошо ещё, что для нужных мне картостилей не пришлось полноценно разбирать синтаксис eval()-выражений, иначе код разросся бы ещё развесистей.
Любопытно, что поначалу я экспериментировал с генераторами парсеров (LALRPOP и nom), но затем по совокупности факторов отказался от этой затеи и написал токенизатор/парсер вручную:
{{{{{{{{ (CC BY-SA 3.0) его сражает непонятно откуда берущийся комбинаторный взрыв.Безусловно, строчек кода в ручном токенизаторе/парсере получается больше, см. хотя бы функцию, читающую вещественную число. Но пишутся и читаются они достаточно прямолинейно, покрываются тестами вообще идеально, да и вообще, человека видевшего изнутри любой токенайзер для нужд NLP, сложно чем-то напугать.
Звучит чертовски странно, но отрисовка линий — это самое сложное место во всём рендерере. Я переписывал его полностью несколько раз, пытаясь добиться удовлетворительного результата, и каждый раз был опасно близок к тому, чтобы плюнуть и забросить проект.
Разумеется, обычную однопиксельную линию с помощью алгоритма Брезенхема нарисовать тривиально, но для полноценно выглядящих карт нужны как минимум все следующие варианты:

То есть нужно уметь:
Первоначальный план — подглядеть, как всё это делают Cairo или Skia, и реализовать в упрощённом виде — полностью провалился. Они решают существенно более сложную задачу — рисование векторного пути произвольной сложности, и легко отделимой части, ответственной только за прямые линии, там нету (ну, или я не нашёл).
Про рисование толстых линий после долгих поисков я нашёл две замечательные ссылки: Drawing Thick Lines и The Beauty of Bresenham’s Algorithm. Первую, не очень большую (я в конечном счёте вдохновлялся в основном ей), рекомендую почитать, даже если сама тема вам не очень интересна; на мой взгляд, описанный там алгоритм чрезвычайно элегантен и понятно описан, с картинками и примерами кода. Вторая — это внушительных размеров труд, обобщающий алгоритм Брезенхема на самые различные кривые. Целиком я его, конечно, не прочитал, но из части, относящейся к линиям, почерпнул немало полезного.
С остальным почти полностью пришлось выкручиваться самому. Я вспомнил юность, проведённую на алгоритмических контестах, и несколько выходных подряд рисовал на листочке картинки с отрезками, точками, формулами расстояний, геометрическими тождествами, а затем воплощал это в коде и с лупой сравнивал результат с тем, что выдаёт Cairo. Во всех интересных мне случаях удалось добиться почти попиксельного совпадения, и кода вышло относительно немного, что радует. Не радует, что пришлось использовать вещественные числа вместо целых и применить уйму квадратных корней, делений и взятий остатка. Поэтому красивые толстые линии закономерно вырисовываются на порядок медленнее, чем это мог бы сделать наивный алгоритм Брезенхема.
Ещё стоит отметить, что в спецификации MapCSS есть свойство linejoin, указывающее, как должны выглядеть стыки концов разных линий: в виде треугольника, в виде дуги или как придётся. Эту потенциально интересную задачу я аккуратно обошёл стороной, потому что идей о том, как можно просто реализовать linejoin в рисовалке, у меня не было, а на эстетичность карты места соединения линий удивительным образом практически не влияют (я вообще вспомнил про это свойство, только когда начал писать этот абзац).
Трассы, дороги, тропинки, железнодорожные пути и мосты — это очень важно, но без подписей к ним карта, естественно, бесполезна. Изначально я даже не хотел замахиваться на самостоятельное рисование букв на экране, потому что после первоначального погружения в тему это представлялось мне делом совершенно неподъёмным. Помимо собственно рендеринга шрифтов, для хинтинга в TrueType-шрифтах нужен интерпретатор стековой виртуальной машины, для шейпинга — движок типа HarfBuzz, для эмодзи — поддержка разноцветных символов и так далее. Не чтобы каждая отдельная задача была нереальной, но объём работ в совокупности выглядел безрадостно.
В этот момент мне повезло: я увидел потрясающий пост Inside the fastest font renderer in the world за авторством Рафа Левиена и прилагающиеся к нему исходники без внешних зависимостей, которые сразили меня просто наповал. Код, собственно рисующий буквы, помещался в сотне с небольшим содержательных строк; остальное приходилось на всякие хелперы и развесистый, но скучный и понятный парсинг TrueType-файлов.
Разобраться в этой магии мне очень помогла статья с нарисованными фломастером картинками, ссылка на которую была в посте (статью я, опять же, рекомендую почитать, даже если шрифты в целом оставляют вас равнодушным). Оказалось, что хинтинг в 21-м веке не сильно-то и нужен, и если смириться с тем, что на карте не будет арабских надписей с эмозди, то обычные русские или английские подписи рисуются очень легко, даже если учитывать кернинг. А если поиграться с арктангенсами и научить буквы загибаться вслед за дорогами, то становится прямо очень неплохо:
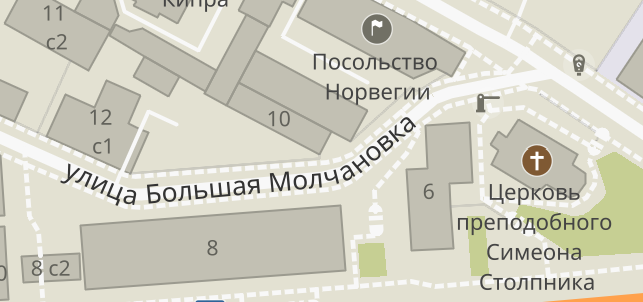
На этом можно было бы и успокоиться, но есть ещё один тонкий момент: для некоторых геообъектов (в основном домов сложной конфигурации) центр или центроид объекта может быть не лучшим местом, чтобы разместить надпись. Например, для этого круглого дома:
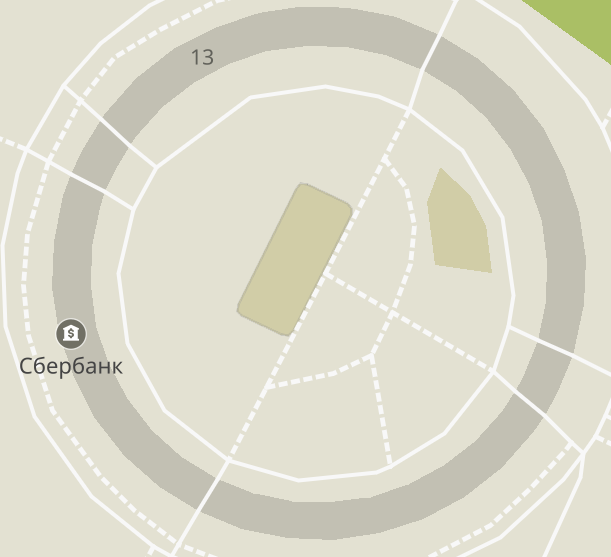
Когда я осознал проблему, решение, внезапно, долго искать не пришлось: для этой задачи Владимир Агафонкин придумал клёвый и, кажется, уже канонический алгоритм с названием Polylabel (рекомендую почитать, даже если… ну, вы поняли). У себя я реализовал чуть видоизменённую модификацию этого алгоритма из Mapnik под кодовым названием interior — она даёт чуть более эстетически привлекательные результаты за счёт того, что при прочих равных старается расположить надпись ближе к центроиду.
Последними (я надеюсь) граблями, на которые я наступил в рендеринге шрифтов, был catastrophic cancellation в уже полностью реализованном и работающем Polylabel — я совершенно случайно заметил, что в некоторых весьма прямоугольно выглядящих зданиях номер дома располагается подозрительно близко к углу. Интереса ради можете попробовать проверить свою интуицию и прикинуть, какой из трёх алгоритмов вычисления центроида даёт результаты, больше всего похожие на правду, а также честно признаться себе, ожидали ли бы вы подвоха в этом месте.
Когда рендерер, наконец, полноценно заработал, запал у меня уже совсем пропал, поэтому в плане оптимизации я пока сорвал только самые низко висящие в профайлере фрукты:
Все семплирующие профайлеры, которыми я привык пользоваться при работе с C++, отлично работают и с Rust (perf для Linux, Instruments для macOS, Very Sleepy для Windows). В дополнение к ним я написал ещё трассирующий фреймворк, показывающий, сколько в среднем тратится времени на каждый этап отрисовки плитки:
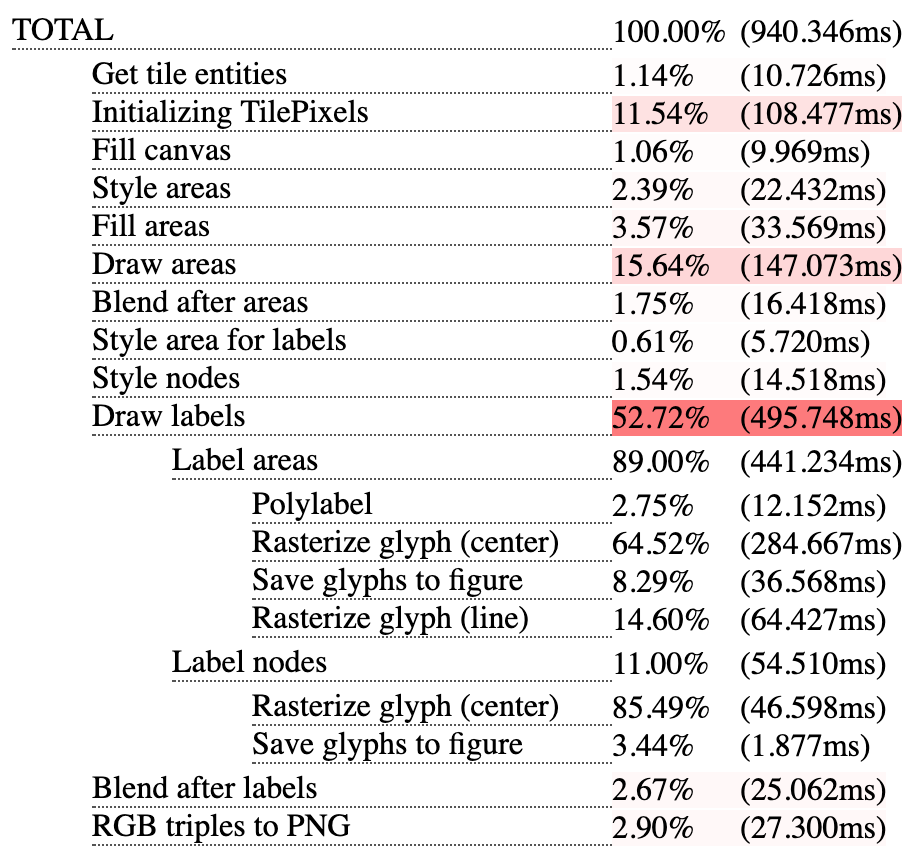
Тут отчётливо видно, что в первую очередь надо разгонять отрисовку текста, во вторую — отрисовку линий. Заодно видно, что я забыл вставить трассировку времени, которое тратится на инициализацию того самого общего буфера, и только при подготовке этой заметки обнаружил, что там расположен ещё один предельно низко висящий фрукт (но также видно, что я очень честный и не стал этот позорный факт скрывать).
В заключение ещё хотелось бы немного рассказать о слабых и сильных сторонах языка Rust в качестве замены C/C++. Незаметно для себя я уже написал на нём несколько тысяч строчек кода (весь рендерер занимает шесть), что не очень много, но достаточно, чтобы делать какие-то выводы.
Слабые стороны можно сжать в три слова: ОМЕРЗИТЕЛЬНО МЕДЛЕННАЯ КОМПИЛЯЦИЯ. Возможно, я что-то делаю не так, но после любого однострочного изменения сборка в релизе занимает где-то 30 секунд. В дебаге поменьше (секунд 8), потому что работает инкрементальная компиляция, но полноценно пользоваться дебажной версией ожидаемо невозможно — тормозит.
Сильные стороны тоже описываются тремя словами: это всё остальное. Самое приятное, наверное, что программа без всяких санитайзеров гарантированно не упадёт в сегфолт из-за очередного use-after-free или случайно забытого мьютекса.